【微服務架構如何通吃1億筆異質行為資料】國泰金控資料分析關鍵框架HIPPO大公開

國泰金控首次公開了自家資料分析的關鍵框架HIPPO,揭露了這套分析基礎架構的樣貌(攝影/洪政偉)。
如何更了解顧客(KYC)是金融業一直想要從龐大資料中回答的關鍵挑戰,隨大數據技術和資料科學的崛起,臺灣金融圈近兩年也積極成立資料科學團隊,招募資料科學人才,但如何更快更有品質地從龐大資料中找出有價值的情報,卻是各家金控和銀行業者秘而不宣的關鍵。直到最近,國泰金控首次公開了自家資料分析的關鍵框架HIPPO,揭露了這套分析基礎架構的樣貌。
在國泰金控數位暨數據發展中心資料科學研發科中擔任資料科學家的陳榮錡指出,資料分析的挑戰是,除了要統整來自十多種資料源的異質資料,還要面對不同高度客製化的分析需求,過去國泰的分析人員、資料科學家多半只能採取偵探式的資料探索方式,按每次分析需求逐一解決。
但是,這種偵探式分析方法終究不是長遠之道,因此,國泰想要打造出一套系統化的資料分析框架,來通吃多樣性資料源,又滿足不同客製特色的分析需求。最後,才發展出這套國泰稱為採用「資料微服務架構」設計的HIPPO架構。
早在2016年中,國泰集團就在金控下成立了數位暨數據發展中心,來統整旗下金控、銀行、人壽、產險、證券各子公司的金融科技發展。而陳榮錡所在的資料科學研發科,更被視為是國泰資料科學實驗室,目前約有11名成員,從去年就開始打造這套新一代的HIPPO資料基礎架構,也從2016年10月開始建立客戶歷程資料,目前已累積數十種交易資料,以及上億筆來自銀行、人壽和證券的消費者行為資料。
拋棄偵探式作業方法,靠系統式作法才更有效率
來自銀行、人壽、證券這三個子公司匯集的資料相當豐富,也分別代表了不同領域的金融情報。
例如,銀行資料主要包含用戶的投資、理財、存款資訊;人壽業務儲存了保險、保單資料;證券則是股票買賣等資料。因應業務不同,衍生出不同的資料,因此資料儲存格式、維度都完全不一樣,但是,國泰資料科學家團隊的任務是,「從單一公司格局,轉而綜合剖析各產業資料,得到最大綜效。」也因此,無論如何,國泰資料科學團隊的挑戰就是,得想辦法彙整來自三家子公司的龐大資料。
再加上,國泰金控旗下各子公司因業務特性不同,資料處理流程也有不小的差異。陳榮錡舉例,銀行每天三點半閉門進行結算,但證券資料則是受限於股票交易時間,「起始時間都不一樣,資料非常難整合,」他表示,由於子公司各有獨特作業程序,也不可能要求全面統一作業流程,資料源頭的控制很難。
為了因應資料多樣性的問題,國泰資料團隊將資料屬性進行細部拆解,「每筆資料都能回推至特定的行為」,像是購買者的身分、消費行為、購買物品、時間點、使用通路,如此讓各子公司的資料能建立統一化的資料格式。國泰也設計了一套統一的Data Schema。子公司的資料先匯入Hadoop平臺,由相關作業人員將其轉換成符合客戶歷程資料庫的統一格式,同時進行檢查來確保資料品質,才會匯入客戶歷程資料庫。

統一資料後的目標,打造用戶消費行為動態牆
當資料具備統一性之後,陳榮錡表示,就可以用來打造出一個像臉書動態牆般的國泰用戶歷程訊息牆。他進一步解釋:「分析人員只要輸入用戶專屬ID,就可以在一個動態牆網頁上,按時間序列一一呈現出,這個顧客過去的消費行為。」就像臉書動態牆上,按時間序列呈現出使用者生活大小訊息,像是打卡、影片或是貼文等各類資料
不過,資料彙整作業中,國泰碰上兩大挑戰。第一個困難是資料源更新時間的不確定性,第二個挑戰則是相依資料源的處理。
他舉例解釋,曾有資料分析人員想要利用客戶歷程資料庫的資料,進行S統計分析,但也想要匯入MongoDB,供業務單位應用系統即時存取之用。這位分析人員所需要的不只是單一資料來源,還需要結合各公司、不同業務部門的資料,「必須要等待前端的資料都收集完成才能進行。」因此得設計一個機制,當需要的資料都已備齊時,就通知分析人員開始進行統計分析。
設計全新的資料微服務框架,讓資料處理系統化
龐大資料的前置處理,成為國泰資料分析的第一個瓶頸。陳榮錡比喻,過去的作業方式很像「偵探辦案」,當團隊收到任務時,首先要判定資料的源頭,究竟是來自銀行、人壽抑或證券。接著,再從這堆資料中,尋找分析作業所需要的資料屬性(Attribute)或是資料維度,「最後則是拼湊線索,找到可能的事發原因。」但這種偵探辦案方式,每次碰到新需求都得要重新開始進行,「由於國泰金融事業多元,資料高度多樣化,導致前置處理成本相當高。」
因此,陳榮錡表示,資料團隊希望可以設計一套標準架構,改變舊有作業流程,演進成系統式作業方法,不需要每次碰上新問題,都得要從頭開始累積,「讓資料科學家、分析師可以從事真正有價值的事情。」因此,資料團隊也開始著手設計微服務資料系統,自行建構專屬的HIPPO框架。
國泰設計HIPPO框架想要做到三項目標:響應式、模組化及可監控。陳榮錡解釋,響應式設計目的是為了解決資料源不定時更新的資料非同步問題,而模組化設計需求,則是要解決資料源高度相依性而衍生的服務相依性問題,而最後一項可監控設計,是因為資料團隊成員大部分原先都是來自軟體公司,「因此我們很在意系統的健康狀態。」因此資料團隊也設計了系統監控工具,確保系統模組運作正常。
三大設計特色:微服務架構、被動式訂閱和水平擴充
為了要滿足上面三個要求,陳榮錡表示,國泰採用了三個作法來設計HIPPO框架,除了採用微服務架構外,還得搭配被動訂閱式流程,以及水平擴充能力。
在微服務架構的設計上,陳榮錡表示,過去國泰資料處理流程上,會將完成一項任務所需要的每個步驟,開發出對應的程式模組,例如有四個步驟,就開發出A、B、C、D四個模組,A模組執行完畢,再執行B,如此依序執行到D。但在HIPPO框架的微服務架構設計中,所有元件都是透過API溝通,每個步驟會開發成獨立的模組,來降低各模組間的相依性,例如可以依序執行ABCD,也可以是ABE或ABCDF等任意組合。不同分析任務中的共同功能需求,就可重複利用相同的。「這個架構讓資料處理的分工更容易,也適合放到雲架構。」
靠微服務架構,簡化了分工問題。第二個HIPPO框架的設計重點是被動式訂閱流程。國泰過去的作法是主動式呼叫,例如若有一項任務需要依序執行A、B、C、D元件,每個元件執行完畢後,主動呼叫下一個元件,例如A完成後,由A來呼叫B接手處理。
但「在HIPPO框架中,則改為被動式驅動」,也可說是一種是由事件驅動運算的設計。當A元件完成後,不會主動呼叫下一個元件,除了保存運算結果之外,也將「A元件執行完成」的狀態訊息和運算結果,發布到一個陳榮錡稱為Mailbox的事件管理系統上。反而是由B元件監聽Mailbox,一旦看到出現了「A元件執行完成」的狀態資訊,B元件自己就可以接手處理。同樣作法,B元件完成後,也只是將完成狀態發布到Mailbox上,等C元件自己發現而啟用處理。
陳榮錡解釋,過去的「主動式呼叫」簡單來說就是「就是自己做完,呼叫下一個執行者。」,而現在的「被動式驅動」作法,則是「有事情就做,沒事情就休息。」的概念
「這樣的方式的優點,可以減少程式修改的麻煩」,他舉例,未來如果有一個任務需要B元件的運算過程時,不用像過去那樣得修改B元件的程式碼,才能增加要呼叫的對象,而是讓新任務中的新元件自己來監聽Mailbox中的訊息,若看到出現了「B完成」的事件標題,新元件就可以從Mailbox取得B處理後的資料繼續接手處理。
而第三個設計原則是水平擴充原則,因為每一個運算元件都是獨立運作的API微服務,若有不少任務都需要執行相同的元件時,例如C元件,就可以單獨擴充多個C元件的副本來分散運算負載,來提供水平擴充的能力。
HIPPO框架套用到國泰金控客戶歷程處理上,國泰資料團隊將原本從Hadoop資料湖,分別設計了不同的微服務,包括了用來監聽資料湖完成訊息的Frontier元件、將資料轉成「歷程」格式的Batch-ETL元件、處理「顧客」為主的格式的DB-ETL元件、還有及時查詢「顧客」實踐的Query元件,另外還包括了用來監控健康與控制服務狀態的Manager元件。
他舉例這些元件的運作關係,資料分析任務第一個需要呼叫的微服務就是Frontier,其任務是監控資料池內數據的狀態,監控資料的更新、處理等事件。當資料處理完成之後,Frontier服務就會在儲存空間Mailbox放置Flag狀態訊息,標示資料湖的任務已經完成。
接續的是Batch-ETL服務,將資料轉成統一資料格式後,再把資料匯入客戶歷程資料庫。當任務完成後,它也會上傳完成任務的狀態訊息到Mailbox。
而DB-ETL服務則負責將客戶歷程資料,轉換成MongoDB所需要的格式,或是執行一些統計分析、資料維度的轉換。再者是Query服務,收到來自DB-ETL的通知後,使用者就可以自由使用MongoDB中的資料。而Manager服務就會持續監控各個服務的運作狀況,檢視各元件的健康狀況。除此之外,陳榮錡表示,國泰資料團隊正在著手打造的機器學習、串流式ETL服務,「也都符合被動式訂閱、微服務架構的設計原則。」

過去國泰並未導入微服務架構時,每次要處理一個任務,得要拆解成多個步驟,依序執行每個步驟的程式模組來進行資料處理。當A流程之後,再依序呼叫B、C流程,在新架構,所有模組元件則改透過API溝通,降低各模組間的相依性。
圖片來源/國泰金控
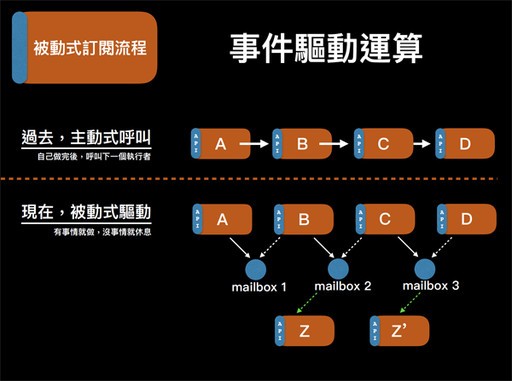
過去是在每一個元件執行結束時,自動呼叫下一個元件來接手,如A完成時呼叫B,B完成則呼叫C。但在HIPPO新架構中,元件執行完成後,將完成狀態發布到Mailbox事件管理平臺上,改由B元件主動訂閱Mailbox,若收到A的運算結果後,B元件就會開始接手執行,再將處理結果儲存到Mailbox。
圖片來源/國泰金控

結合了微服務架構和被動式訂閱的設計後,每一個元件間各自獨立,彼此之間的呼叫串接也可以透過Mailbox服務來仲介狀態事件的驅動。如此一來,就可以針對單一元件進行擴充,例如 C元件需要大量運算時,就可以啟用更多這個C元件的微服務。
圖片來源/國泰金控
使用開源解決方案,培養自家資料科學人才
而國泰資料團隊也使用了許多開源技術,像是Hadoop、Spark、Akka、Kafaka等大數據工具。
陳榮錡表示,過去臺灣的傳統產業多半仰賴外部廠商的解決方案,「但是資料科學發展太快,而開源專案上也有許多相對應的解決使用方案」,因此國泰也開始培養自己的資料科學人才,搭建一套專屬國泰的後端資料系統。
而這些資料處理框架,未來在金融、保險業務上也有許多種潛在應用。他舉例,像是客群網路的建立,如果將用戶視為每一個獨立節點,「每節點間又有存在連結」,像是地址、電話、親屬關係、贈送關係、轉帳。他舉例,雖然某些資料節點內儲存的姓名資料不同,但是地址都相同,「這些相關節點可能就是一個大家庭的成員」,在分析出這些資料節點的共通性後,未來若想要推出家族式的保險,「這些彼此存在關聯的節點,都是潛在的銷售對象。」
再者是潛在客群的尋找。陳榮錡表示,資料團隊目前已經在實驗「旅遊標籤」功能的效用。他解釋,該團隊過濾出過去30天內,曾經購買旅遊商品的用戶,例如,海外住宿、機票、旅行支票等產品。若有相關購物行為,資料團隊會將這些用戶貼上旅遊標籤。在這組A樣本中,總共有超過1萬個相異用戶。而另外一組的B樣本用戶,則可以挑選出過去一個月內沒有購買旅遊商品,這組B樣本可能約有6.7萬人。
經過資料團隊的比對,發現在一兩周內,A樣本中的用戶總共有超過43,00人有實際購買旅遊商品,比例達到43.2%。反之,B樣本中12%購買旅遊商品,大約為8千多人,「被貼上旅遊標籤的用戶,以成交率來說高出了3.6倍。」
同時,資料團隊也比照與旅遊標籤相同的實驗方式,尋找是否有資金需求的用戶。陳榮錡表示,在貼上標籤的樣本中,後來有實際資金需求的用戶,申請貸款的比例高上了11.94倍。

圖片來源/國泰金控
人工智慧得建立在良好的資料基礎架構之上
回顧過去1年多在資料科學團隊內的工作經驗,陳榮錡表示,許多人都想要做資料科學,「很多人都是採用偵探式的作業方式」,從無到有開始,探詢、摸索資料背後潛在的意義或洞見,「這樣做法,水平擴充性不佳,許多工作也必須從零開始。」也因此,陳榮錡表示,國泰資料科學團隊花上了一年,建立資料科學的基礎架構,「只有良好的基礎架構,資料科學家才有更多時間進行資料分析」,而不是浪費無謂的時間處理資料。
另一個挑戰是,資料科學團隊儘管有不少創意發想,但許多主管機關還未開放的共同行銷應用,得取得使用者授權才能進行,但一般大約10~20%的使用者同意授權資料的使用。陳榮錡指出,資料科學團隊要突破的困難是,如何在多數用戶未同意使用的狀況下,找出合法可行的應用。
《全文請見iThome(https://www.ithome.com.tw/news/118516)》
