IBM發表機器學習瘦身術,讓大型深度學習訓練模型精簡95%,連在手機上都能跑
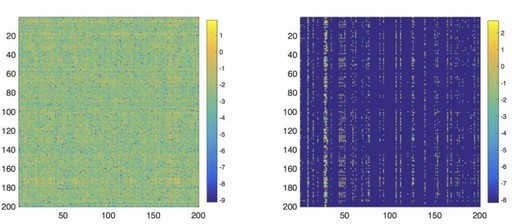
Net-Trim可以修剪掉類神經網路中超過93%無用的神經元,大幅縮小龐大的訓練模型。左圖為修剪前,右圖為修剪後(圖片來源/IBM)。
IBM研究所研究員Nam Nguyen在2017年NIPS會議發表論文,揭露研究中的人工智慧最佳化框架Net-Trim,以分層凸集架構( Layer-wise convex scheme)來修剪精簡預先訓練的深度類神經網路模型,解決大型機器訓練模型在嵌入式系統運作資源短缺的問題。
隨著技術的發展,從影像辨識到語言翻譯,深度學習逐漸成為人工智慧應用程式的首選,而為了增加結果精確度,開發者使用更多的資料以及更多層的深度學習網路,以期得到更好的結果,然而越龐大的訓練模型意味著需要更多的運算資源,不過對於運算資源有限的嵌入式系統來說,如果這些龐大的預訓練模型無法在上頭運行,那也是徒勞。
Nam Nguyen與其團隊開發的Net-Trim,能夠在不犧牲精確度的情況下降低機器學習訓練模型複雜度。其中一個工作便是移除冗贅的權重值,讓網路變的稀疏。常見的方法便是使用L1正規法(L1 regularization),但是這個方法在深度學習無用武之地,部分原因是因為跟深度學習相關的公式為高度非凸性。
Net-trim能找到每一層網路中最稀疏的一組權重,並維持輸出與起始訓練的回應值一致。使用L1鬆弛(L1 relaxation),由於整流器線性單元活化是分段線性的,因此允許透過解決凸程式來搜尋。
訓練資料在類神經網路一層一層的往下傳遞,Net-trim在結果輸出與前置預算網路的回應值一致的前提,每一層以最佳化架構提升權重稀疏度。Net-Trim其中一項優點便是能使用凸公式(Convex formulation),能夠適用各種標準凸優化。
而Net-Trim於其他修剪方法不同之處在於,Net-Trim方式是數學可證的,在學習網路修剪前與修剪後維持相似效率。另外,與其他使用閾值修剪的方法相比,Net-Trim在第一次修剪完後,不需要再花其他多重再訓練的步驟。而且受惠於Net-Trim後處理階段的特性,Net-Trim可以搭配各種最新的類神經網路,再縮小模型大小之餘,還能增進模型的穩定度以及預測精準度。
《全文請見iThome(https://www.ithome.com.tw/news/119572)》
